A presentation at Iceberg Summit 2025 in in San Francisco, CA, USA by Viktor Gamov

One Does Not Simply Query a Stream! Viktor Gamov, Confluent @gamussa Iceberg Summit April 8, 2025 @gamussa | @confluentinc | @apacheiceberg
@gamussa | @confluentinc | @apacheiceberg
Viktor GAMOV Principal Developer Advocate | Confluent THE CLOUD CONNECTIVITY COMPANY X and Bluesky: @gamussa Kong Confidential
Simpler times Monolith @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
Simpler analytics ETL and CDC @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
Data Pipelines Streaming data pipelines and Microservices @gamussa | gamov.dev/rel | @ConfluentInc
LOG @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
OLTP stream vs OLAP vs. OLTP in Streams OLAP streams @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
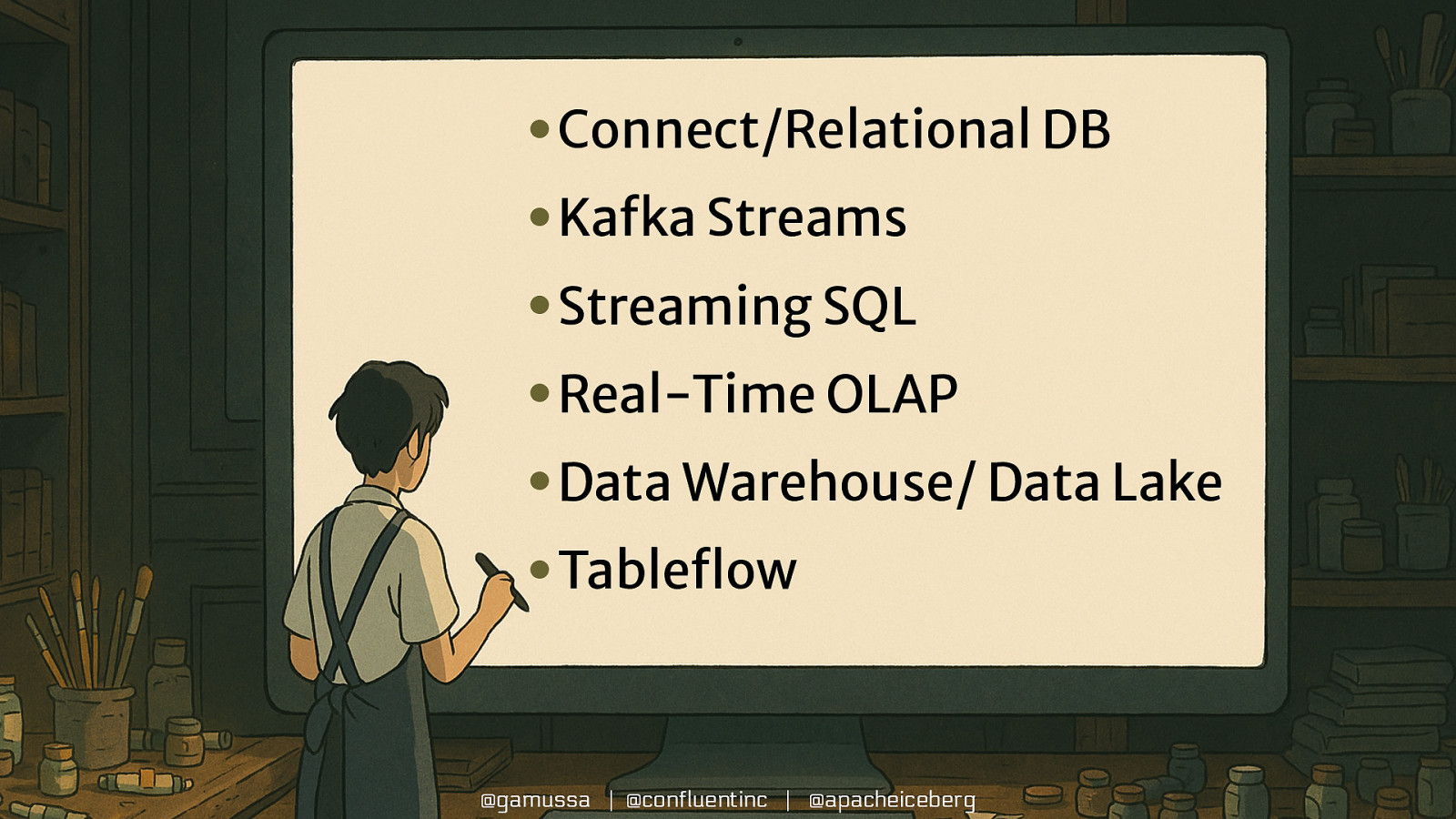
• Connect/Relational DB Our Options • Kafka Streams • Streaming SQL • Real-Time OLAP • Data Warehouse/ Data Lake • Tableflow @gamussa | @confluentinc | @apacheiceberg
Kafka Connect @gamussa | @confluentinc | @apacheiceberg
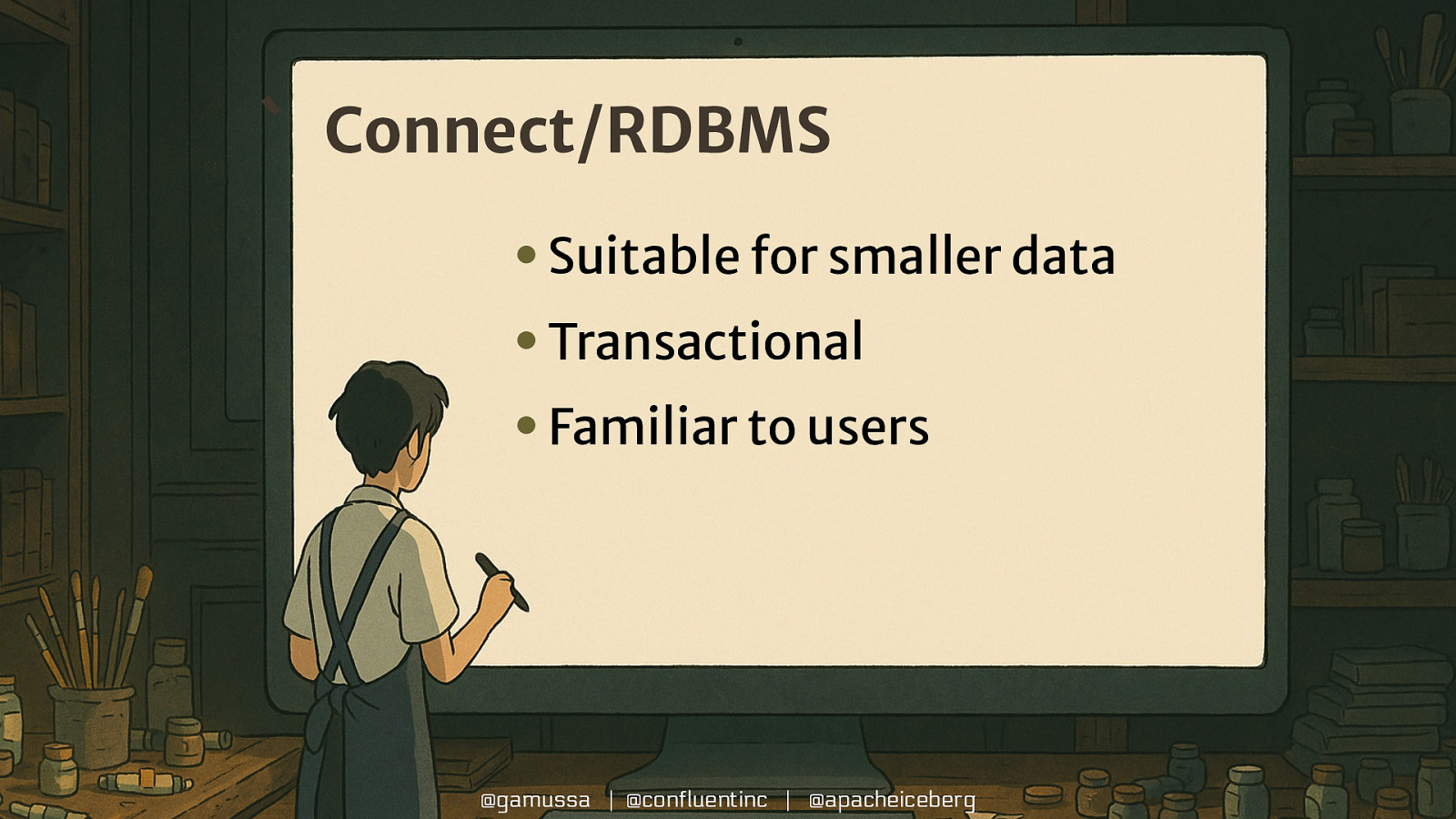
` Connect/RDBMS • Suitable for smaller data • Transactional • Familiar to users @gamussa | @confluentinc | @apacheiceberg
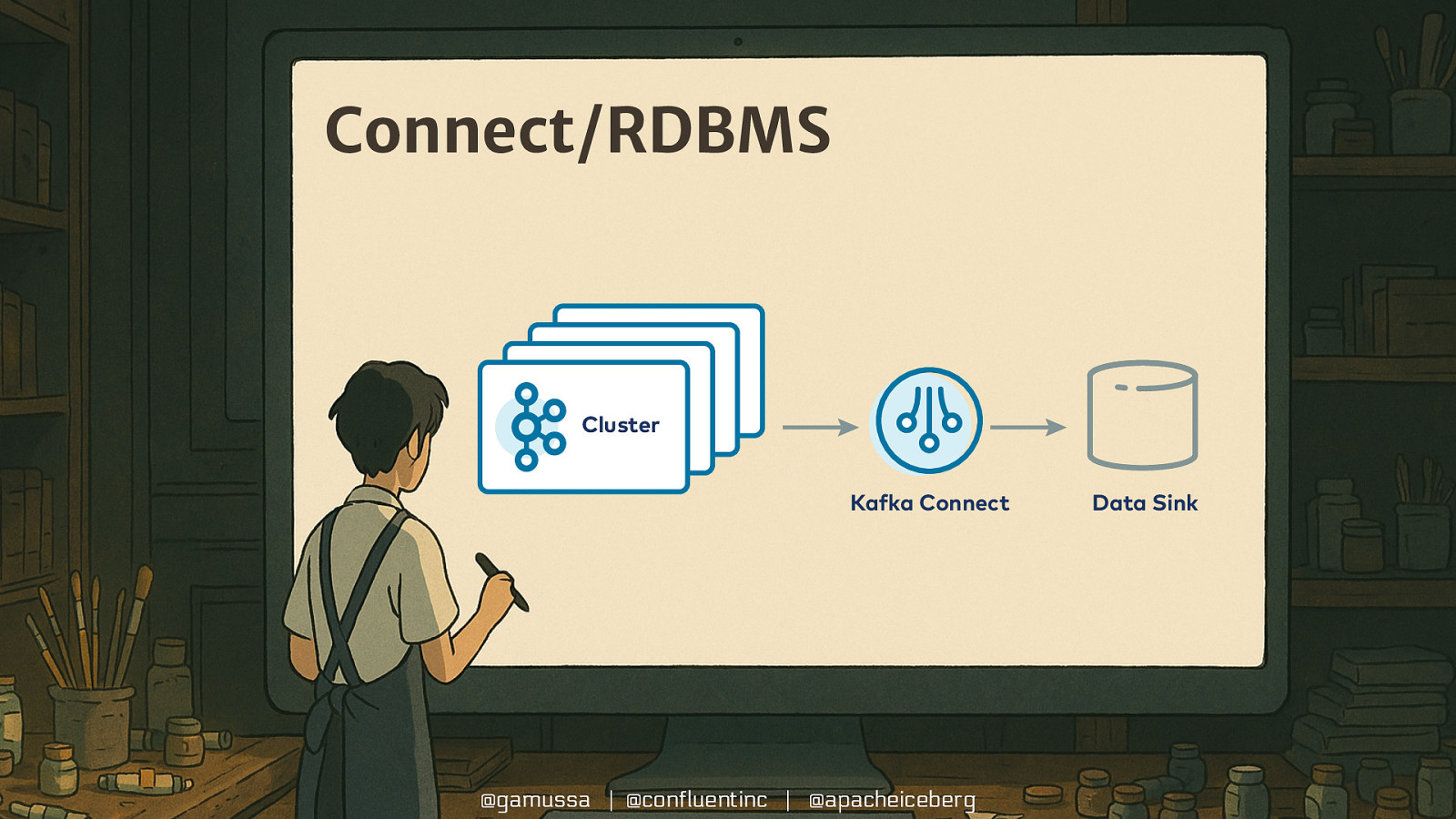
Connect/RDBMS Broker Broker Broker Cluster Data Source Kafka Connect Kafka Connect @gamussa | @confluentinc | @apacheiceberg Data Sink
@gamussa | @confluentinc | @apacheiceberg
Kafka Streams @gamussa | @confluentinc | @apacheiceberg
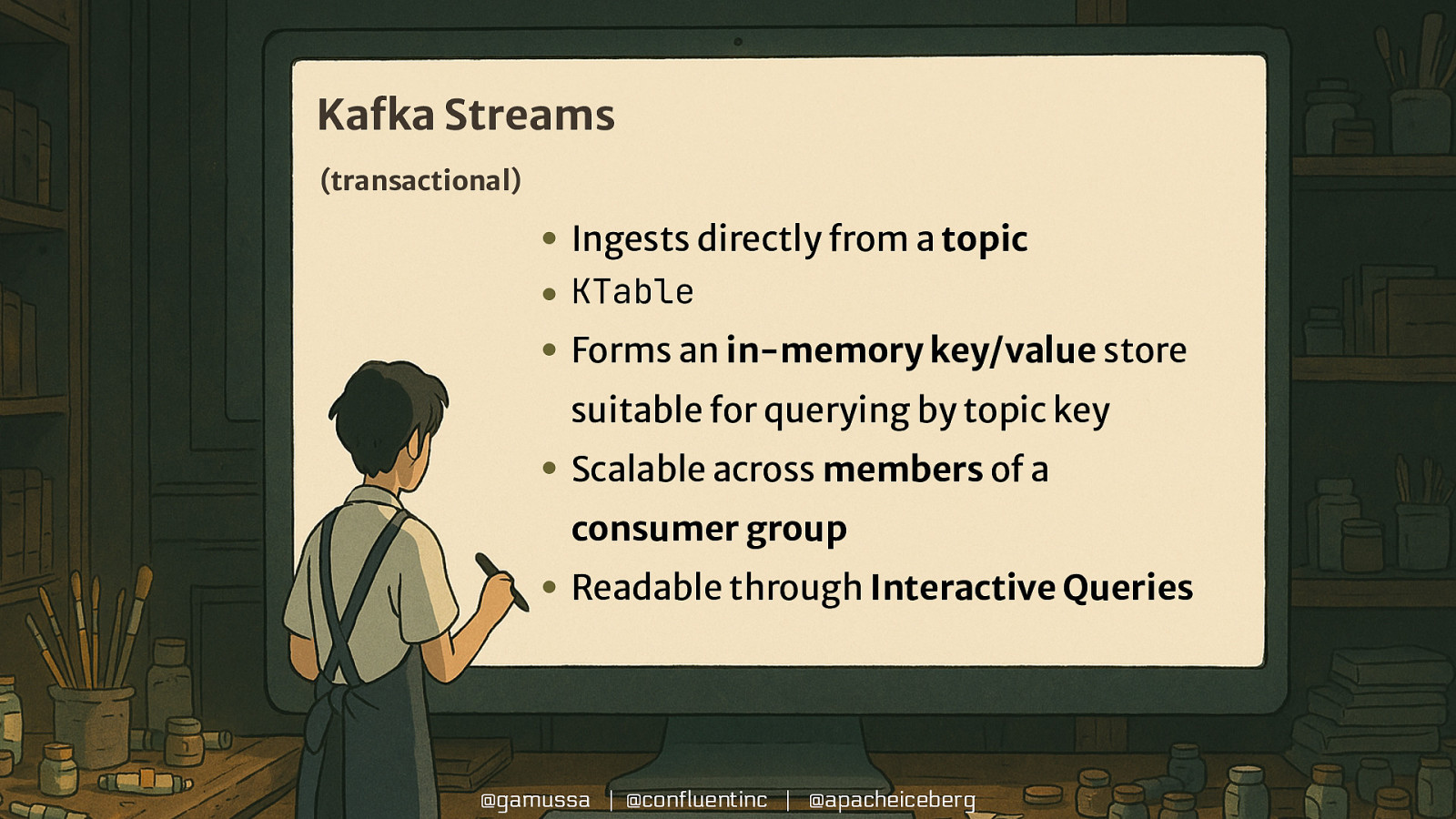
Kafka Streams (transactional) • Ingests directly from a topic • KTable • Forms an in-memory key/value store suitable for querying by topic key • Scalable across members of a consumer group • Readable through Interactive Queries @gamussa | @confluentinc | @apacheiceberg
Kafka Streams (transactional) KStream<String, String> stream = builder.stream(inputTopic, Consumed.with(stringSerde, stringSerde)); KTable<String, String> convertedTable = stream.toTable(Materialized.as(“streamconverted-to-table”)); @gamussa | @confluentinc | @apacheiceberg
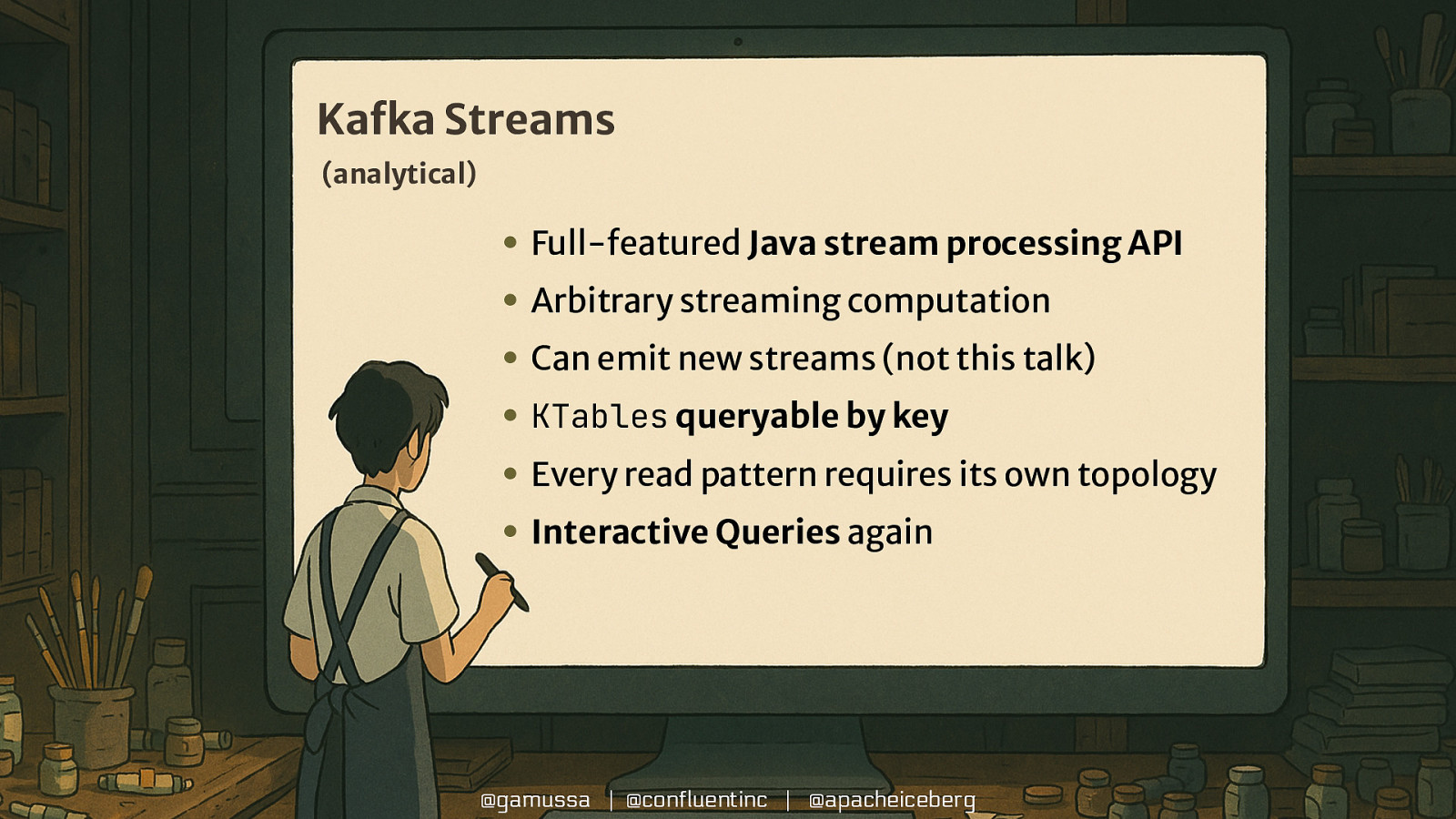
Kafka Streams (analytical) • Full-featured Java stream processing API • Arbitrary streaming computation • Can emit new streams (not this talk) • KTables queryable by key • Every read pattern requires its own topology • Interactive Queries again @gamussa | @confluentinc | @apacheiceberg
Kafka Streams (analytical) KTable<String, Long> wordCounts = textLines .flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split(“\W+”))) .groupBy((key, word) -> word) .count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as(“counts-store”)); wordCounts.toStream().to(“WordsWithCountsTopic”, Produced.with(Serdes.String(), Serdes.Long())); @gamussa | @confluentinc | @apacheiceberg
@gamussa | @confluentinc | @apacheiceberg
Streaming SQLs @gamussa | @confluentinc | @apacheiceberg
Streaming Database • SQL for Queries • Streaming Source is 1st class citizen • Persistence / Storage @gamussa | @confluentinc | @apacheiceberg
Streaming SQL • ksqlDB • Materialize • RisingWave • TimePlus @gamussa | @confluentinc | @apacheiceberg
But Viktor, Flink has SQL Why not Flink? @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
ksqlDB • «Streaming Database» • Provides persistent TABLE abstraction • Pull and Push queries • Like Kafka Streams, but in SQL @gamussa | @confluentinc | @apacheiceberg
Materialize • Replacement data warehouse • Integrates with Kafka, Postgres, dbt • The Materialized View is the central abstraction • Views are persistent and queryable • Postgres wire-compatible • Positioned as an analytics solution @gamussa | @confluentinc | @apacheiceberg
Rising Wave • Distributed SQL Streaming database • Cloud and OSS versions • Implementation of Flink in Rust • Kafka, Pulsar, Kinesis integrations • Flink+persistent views • Postgres wire-compatible @gamussa | @confluentinc | @apacheiceberg
@gamussa | @confluentinc | @apacheiceberg
Real-Time Analytics Database
Real-Time OLAP • Designed for high concurrency, low latency queries • Ingests from streaming and batch sources • Intimate integration with Kafka • Conventional tables and SQL @gamussa | @confluentinc | @apacheiceberg
Real-Time OLAP • Analytics shaped like real-time data • Analytics when users are decision makers @gamussa | @confluentinc | @apacheiceberg
Cloud Data Warehouses
Cloud Data Warehouses
Cloud Data Warehouses • The cloud-based heir of legacy DWH • Ingest from batch and streaming sources • Biased towards structured data and batch access
Data Lake @gamussa | @confluentinc | @apacheiceberg
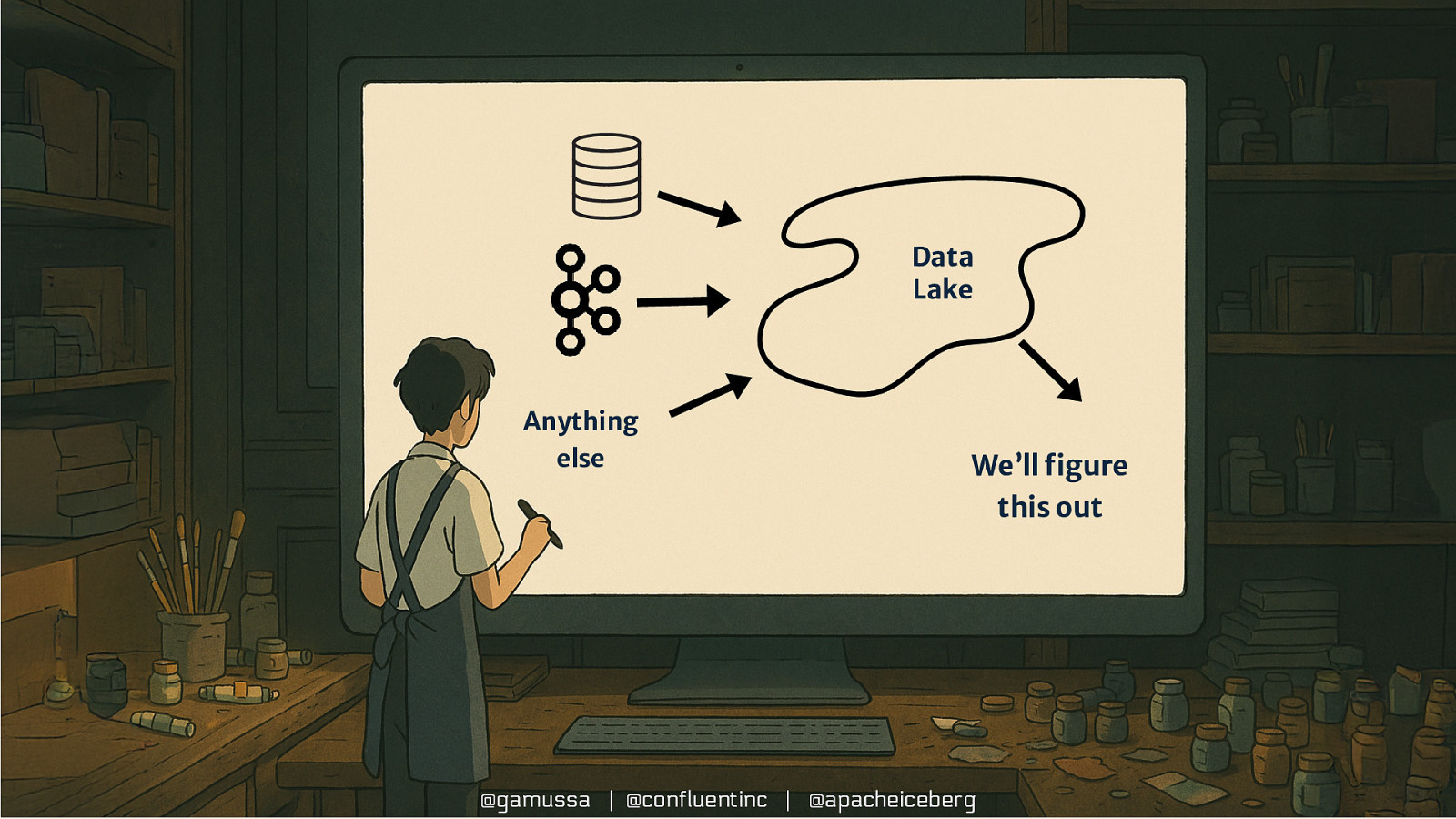
Data Lake Anything else We’ll figure this out @gamussa | @confluentinc | @apacheiceberg
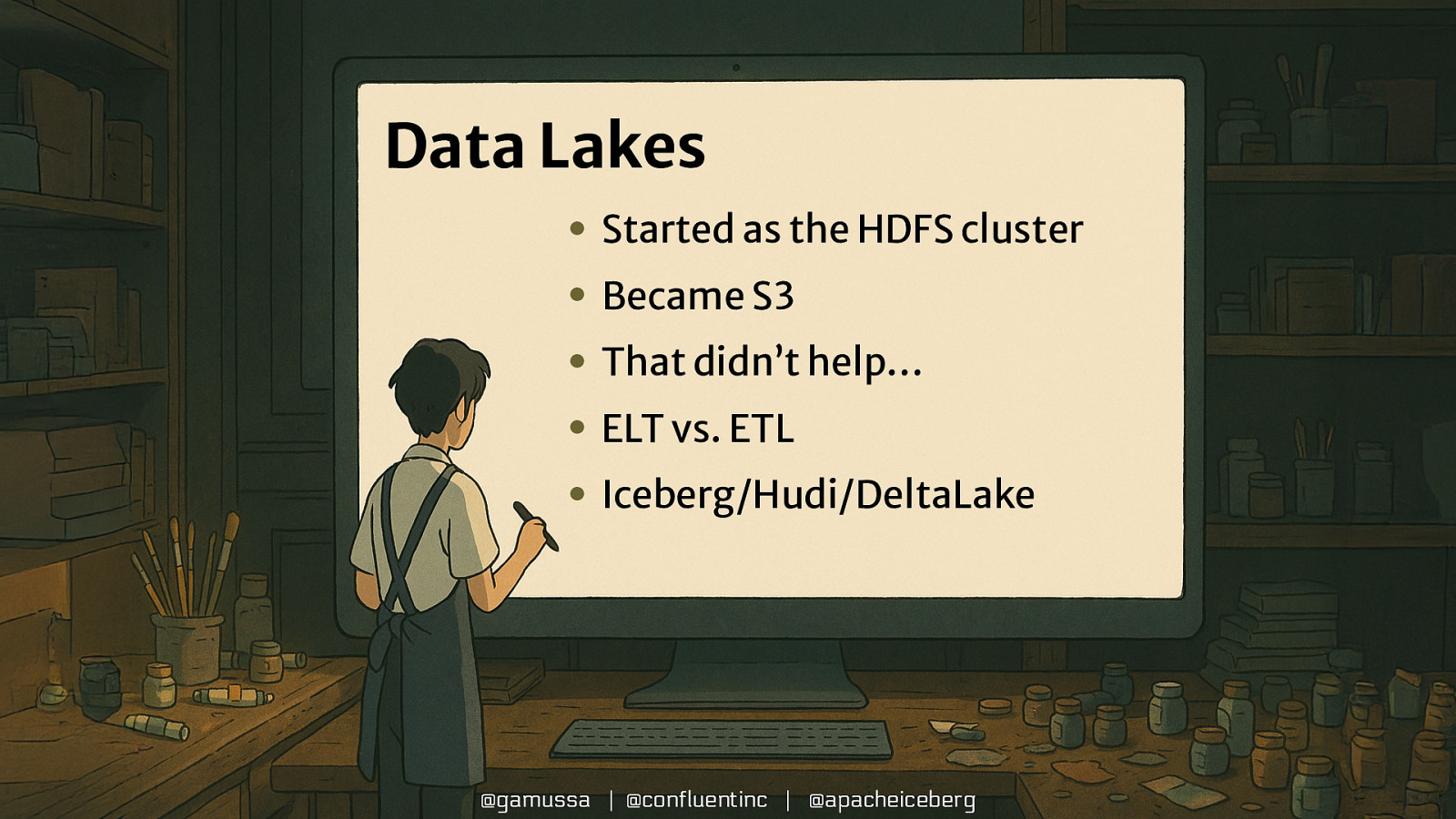
Data Lakes • Started as the HDFS cluster • Became S3 • That didn’t help… • ELT vs. ETL • Iceberg/Hudi/DeltaLake @gamussa | @confluentinc | @apacheiceberg
Data Lakes • Storage and compute are radically decoupled • Structure is relatively less important • Reads are slow • Streaming is historically difficult @gamussa | @confluentinc | @apacheiceberg
Iceberg @gamussa | @confluentinc | @apacheiceberg
Tableflow @gamussa | @confluentinc | @apacheiceberg
@gamussa | @confluentinc | @apacheiceberg
@gamussa | @confluentinc | @apacheiceberg
No Solutions Technology Selection only Trade Offs @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
Sometimes you go with what you know @gamussa | @confluentinc | @apacheiceberg
This is not bad! @gamussa | @confluentinc | @apacheiceberg
Performance Performance @gamussa | @confluentinc | @apacheiceberg
Community/Adoption Community @gamussa | @confluentinc | @apacheiceberg
Differentiated Application Code Area of Exploration Kafka @gamussa || @confluentinc gamov.dev/rel | | @apacheiceberg @ConfluentInc @gamussa
This is not bad! @gamussa | @confluentinc | @apacheiceberg

Streaming data with Apache Kafka® has become the backbone of modern day applications. While streams are ideal for continuous data flow, they lack built-in querying capability. Unlike databases with indexed lookups, Kafka’s append-only logs are designed for high throughput processing, not for on-demand querying. This necessitates teams to build additional infrastructure to enable query capabilities for streaming data. Traditional methods replicate this data into external stores such as relational databases like PostgreSQL for operational workloads and object storage like S3 with Flink, Spark, or Trino for analytical use cases. While useful sometimes, these methods deepen the divide between operational and analytical estates, creating silos, complex ETL pipelines, and issues with schema mismatches, freshness, and failures.
In this session, we’ll explore and see live demos of some solutions to unify the operational and analytical estates, eliminating data silos. We’ll start with stream processing using Kafka Streams, Apache Flink®, and SQL implementations, then cover integration of relational databases with real-time analytics databases such as Apache Pinot® and ClickHouse. Finally, we’ll dive into modern approaches like Apache Iceberg® with Tableflow, which simplifies data preparation by seamlessly representing Kafka topics and associated schemas as Iceberg or Delta tables in a few clicks. While there’s no single right answer to this problem, as responsible system builders, we must understand our options and trade-offs to build robust architectures.
The following resources were mentioned during the presentation or are useful additional information.